Autonomous Car Parking Simulator using Unity MLAgents
How do we simulate an AI to find a parking spot? and then park the car?
Problem Statement
The problem is simple, there's a car in a parking lot, and there is a parking spot at a random position and the Job of the AI is to find the parking spot in it maybe there is a person walking by so the AI has to make sure it avoids hitting the person, as well as avoiding hitting other parked cars
This seems like a perfect case for reinforcement learning and Unity can even help us simulate the environment and look at it in real time to see the AI park the car avoiding the obstacles
Link to the video walkthrough of the project
Environment Setup
Using a few free assets from the unity asset store I found this simple vehicle pack and this simple human asset once I had the basic assets gathered and ready I created the environment that looks like this

Overview of the environment
The environment consists of a parking lot with certain cars, already parked, and the agent car that is looking for a parking spot. To ensure there is not one specific parking spot that is available or vacant, I have randomized the spot and other parked cars, as well as the agent car that requires to be spawned in different positions of the parking lot and in different orientations as well.
Note: All the cars and the vacant spots are generated randomly with a chance of 85% that the spot will be occupied. So, there might be some episodes where there are no vacant spots in the lot, which encourages the agent to look through the whole parking lot for the spot.
Building the environment
- Parking Area
- randomSpawnCarsAndParking() This method helps randomly spawning either a car or a parking on the positions marked in blue diamonds in the above image
- clearParking() This method allows the area to be cleared for next random spawning once the episode ends
- resetArea() This method is created to call the above two functions one after the other from the agent script
- Car Setting
- Collision Detection Scripts This script contains the variable for margin multiplication where the agent car would spawn, the larger the margin the more difficult it is to train, as the agent car would spawn randomly at different locations
-
obstacleDetect.cs
This script will detect when the agent car collides with any of the spawned parked cars, and call the hitACar() method inside the agent script
-
wallDetect.cs
This script will detect when the agent car collides with the side walls of the parking lot and call the hitAWall() method inside the agent script
-
parkingDetect.cs
This script will detect when the agent car properly finds the empty parking spot and drives to it. It will call the parked() method inside the agent script
I created the parking lot which is a square shaped plane with walls on the sides, the area has multiple spawn positions, for randomly spawning the parked cars and the agent car, using script, ParkingArea.cs
Script DescriptionThis script contains the variable for margin multiplication where the agent car would spawn, the larger the margin the more difficult it is to train, as the agent car would spawn randomly at different locations
Configuring the Agent
This is our agent car, the car that needs to find its parking spot. For making sure the car behaves the way it should, I apply following build:
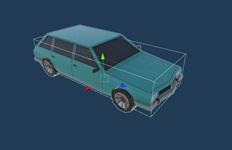
I added wheel colliders onto the front wheels of the car to enable real like driving ability to the car

- Steer Wheels: The two wheels in front will be able to have the steering ability
- Driving Wheels: Considering the car is front wheel drive car I add the driving ability to the front wheels as well. Adding a box collider on the car, with a rigid body that weighs around 1500kg, just to make the car behave realistically.
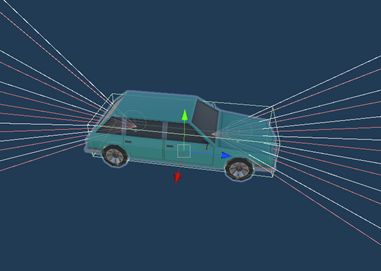
- Adding Ray Perception Sensors
- Behaviour Parameters
-
Vector Action Space Type:
Since this is a case where the agent should be able to partially steer the car, we will be keeping the vector actions continuous
-
Vector action Space Size: 2
The car can either go forward or reverse which constitutes as one action space. Also, the car can turn left or right, which constitutes as one action space. Hence, we use two as the vector action space size.
-
Decision requester:
We keep the decision period to 5 as we don’t want the AI to make a decision before every action. And we also allow the AI to take actions between decisions.
-
Vector Action Space Type:
-
Agent Script (carAgent.cs)
Now we can go ahead and write the agent script Following are the important functions we defined in the script
-
GetRandomSpawnPos()
Get a random Spawn position for the agent car in the center area of the parking lot depending upon the spawn area margin multiplier
-
hitACar()
Punishing the agent for hitting another parked car, we add a reward of -0.1f
-
hitAWall()
Punishing the agent for hitting the wall of the parking lot, we add a reward of -0.1f
-
hitAHuman()
Punishing the agent for hitting the human walking by, we add a reward of -0.3f
-
parked()
Positive reward (+5.0f) for finding the empty parking spot
- OnActionReceived()
-
moveAgent():
This function actually drives the car, depending upon the action received, this method will steer and accelerate the car.
- OnEpisodeBegin():
When we receive an action from the agent, we call the moveAgent method, also we add penalty to make sure the agent improves and tries to perform in least number of actions
Every episode needs to maintain standard values for making sure the AI learns properly, like the car should be stationary at the beginning, so we remove all the forces from the previous episodes. Also, we need to reset the area and randomly spawn the parked cars, and the empty parking spots, which we can do using this function.
-
GetRandomSpawnPos()
Added 3-dimensional ray perception sensors onto the car, in the front and in the back, which would be able to sense objects in 10m range.
Note: Please refer to the script, CarAgent.cs, (path: \CarParking\Assets\Scripts\CarAgent.cs) it is commented with all the details about the functions
Training the Agent
Now that I have configured the agent and the environment, I can move onto the training phase, we need to train this for a significant amount of time so we want to create multiple instances of the environment, so I created about 12 instances

Hyperparameters for PPO
default:
trainer: ppo
batch_size: 1024
beta: 5.0e-3
buffer_size: 10240
epsilon: 0.2
hidden_units: 128
lambd: 0.95
learning_rate: 3.0e-4
learning_rate_schedule: linear
max_steps: 5.0e5
memory_size: 128
normalize: false
num_epoch: 3
num_layers: 2
time_horizon: 64
sequence_length: 64
summary_freq: 10000
use_recurrent: false
vis_encode_type: simple
reward_signals:
extrinsic:
strength: 1.0
gamma: 0.99
summary_freq: 30000
time_horizon: 512
batch_size: 512
buffer_size: 2048
hidden_units: 256
num_layers: 3
beta: 1.0e-2
max_steps: 1.0e7
num_epoch: 3
reward_signals:
extrinsic:
strength: 1.0
gamma: 0.99
curiosity:
strength: 0.02
gamma: 0.99
encoding_size: 256
I added extrinsic reward and curiosity to the agent, so that it will explore a bit more in the parking lot. With gamma as 0.99 the curiosity and the reward diminish every time.
Training Using Generative Adversarial Imitation Learning(GAIL):
For the AI to understand the environment early on, we can provide some demos, so I decided to record 100 demo instances to provide our AI. I played a 100 episode and provided the recorded model for learning by adding its path to the PPO hyperparameters while training.
gail:
strength: 0.02
gamma: 0.99
encoding_size: 128
use_actions: true
demo_path: ../demos/ExpertParker.demo
Results
I trained the agent for 10M episodes, here is a short clip of the inference of the trained Ai







Analysis of the results
- Cumulative Reward
It the agent is training this should be increasing, as the agent will find the parking more efficiently
-
After 30K Steps
- Training 1: 0.2871
- Training 2: 0.08488
-
After 9.99M Steps
- Training 1: 3.252
- Training 2: 4.29
- Episode Length
Should be decreasing, which would mean that the AI is finding the parking spot faster
-
After 30K Steps
- Training 1: 840.2
- Training 2: 896.2
-
After 9.99M Steps
- Training 1: 370
- Training 2: 179.1
-
Value Loss
Correlates to how well the model is able to predict the value of each state. This should increase while the agent is learning, as the policy that it created keeps changing after each and every episode and then decrease once the reward stabilizes, which means that the policy is pretty good at taking actions and is getting the expected rewards at the states. We can train this agent for even longer time, as the value loss hasn’t decreased significantly
-
Policy Extrinsic Value Estimate
The mean value estimate for all states visited by the agent. Should increase during a successful training session
-
GAIL Reward
Should decrease, as the AI stopped taking inference from our demonstrations and learned on his own
-
Learning rate
How large a step the training algorithm takes as it searches for the optimal policy. Should decrease over time. Coincides for both the trainings.
Conclusion
- Can be trained for more episodes: Even though it's converging at about 4M with good enough results, it still sometimes crashes on to sa human or a parked car, Currently ran for 10M cycles and took about 11 hours on an i5 4th generation processor
- Sensors can be added in left and right as well for the agent to get better understanding of the Environment, it currently can not "see" on its left and right and hence sometimes the human walking back and forth crashes onto it, confusing it as to why it got punished and that might change the policy in a weird way, because it won't be able to understand that it is cutting off a human walking